
Hace unas semanas decidí dar mi primera charla pública gracias a la oportunidad que me había ofrecido QALovers. Me puse manos a la obra cuando me lo ofrecieron, pensando que podía aportar desde un punto de vista de calidad. Existen muchos frameworks de testing, muchas herramientas, pero quise ir más allá y reflexionar como realmente mi equipo aporta calidad a los productos digitales que construimos en Cloud District.
En este último año, el equipo técnico hemos puesto mucho esfuerzo en implantar una estrategia de CI/CD, pero echando la vista atrás, para llegar a implantar realmente esta filosofía hemos ido mejorando muchísimos aspectos de nuestro día a día que nos han ayudado a entregar un software de alta calidad.
Sobre este camino preparé la charla y a continuación os voy a contar los puntos más interesantes de esta historia de amor loco.
Antes de empezar
Pero antes de comenzar con esta historia de amor loco, quisiera poner hincapié en algunos aspectos que pueden ayudar a implantar mejoras en el camino, o al menos hacerlo menos duro.
Hablemos de curvas
Durante la crisis del COVID-19, todos podemos incluir en nuestro curriculum que somos expertos en aplanar curvas. Por ello, quiero hablar de la curva de adopción de la innovación. Esta curva se trata de un modelo sociológico que clasifica a las personas en diferentes categorías en función de su disposición a adoptar una determinada tecnología, método o innovación.
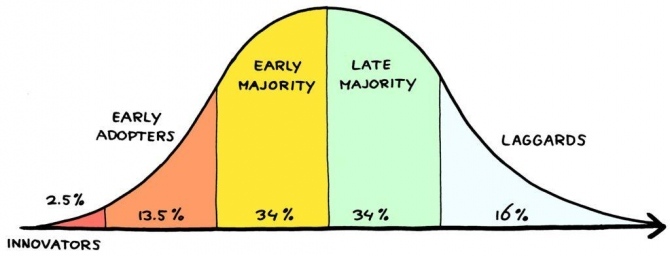
Esta curva puede ayudar en muchos aspectos, sobre todo en el mundo de los emprendedores, para focalizar los esfuerzos en la atracción de un target concreto. Básicamente marca el camino para poner grandes esfuerzos en los entusiastas y early adopters que ayudarán a expandir nuestras ideas.
Esto mismo pasa en muchos aspectos de la vida y en una organización, en la que si quieres hacer que las cosas pasen o implantar una nueva práctica, herramienta o metodología, debes de contar con los aliados que ayuden alcanzar esa masa crítica para que nuestros objetivos tengan lugar.
Pensar en esta curva es muy útil cuando se emprende dado que te ayuda a entender hacia quiénes has de focalizar tus esfuerzos de atracción. Empezar por los entusiastas y los early adopters que nos ayudan a conseguir nuestro objetivo.
Lecturas recomendadas
Sobre esta capacidad de cautivar y conseguir nuestros objetivos quisiera recomendar tres lecturas que pueden ayudar a inspirarte por el camino.
- “Cómo cambiar el mundo” de Jurgen Appelo: ¿Qué puedo hacer con esta pésima organización? Me gusta mi trabajo, pero no me gusta lo que hace la capa de gestión. ¿Cómo lo manejo? Miro a otro lado, me voy a otra empresa o intento cambiar el mundo. Jurgen Appelo es el creador de “Management 3.0” y en este libro ofrece puntos claves de cómo intentar cambiar una organización desde dentro.
- “El arte de cautivar” de Guy Kawasaki. Guy implantó el concepto de “evangelizar” en los negocios tecnológicos, con la idea de atraer y focalizar a usuarios vinculados al mercado Apple. En este libro hay grandes consejos de cómo atraer al público. Y vaya si lo hicieron bien con el lanzamiento de iPhone.
- “Talking with Tech Leads” de Patrick Kua. Si te encuentras en una situación como la mía en el que estás comenzando a realizar un rol de Team Lead, este libro puede ayudarte en el camino. Este Libro relata las conversaciones con Tech Leads con distintos niveles de experiencia. Concretamente 35 entrevistas a diferentes Tech Leads que describen cómo encuentran el equilibrio entre el mundo técnico y el no técnico.
Code Review
Code Review es el proceso mediante el cual los distintos miembros de un equipo revisan en conjunto la implementación realizada por otra persona del equipo. Es algo ligado al software, pero este concepto se puede hacer en otras áreas de la organización como revisión de documentos funcionales, diseño, prototipos, contenido utilizando el concepto de Red Team.

Los Red Teams vienen del mundo del hacking y emulan a los atacantes, utilizando sus mismas herramientas o similares, explotando las vulnerabilidades de seguridad de los sistemas. Pero realmente puedes tener tus propios “Red Teams” que ayuden a sacar punta a nuestras entregas.
Por ejemplo, algunas recomendaciones de mi compañero Joan Llopis a la hora de presentar un documento técnico o revisar un documento técnico de un compañero, deberíamos hacernos este tipo de preguntas:
- ¿Se comprende bien el contenido?
- ¿Cumple con los objetivos que nos hemos establecidos?
- ¿Está adaptado a la audiencia a la que va dirigido dicho documento?
A nivel de software, es importante tener en cuenta algunas buenas prácticas para hacer Code Review, que hemos visto en otros artículos.
Metodología
A continuación se muestran algunas prácticas que nos están funcionando y están impactando positivamente en nuestras entregas a través de la metodología y cultura de empresa.
Contratos ágiles
Los contratos ágiles tratan de romper el paradigma descrito, donde ambas partes comprenden que las estimaciones no son precisas y exactas, sumado a que los riesgos deberán ser compartidos. El contrato pasa a ser un mero trámite y se genera una confianza entre las partes.
Todos deberíamos de asumir que las estimaciones dependen de muchos factores, y aunque pueda haber barreras técnicas, principalmente considero que estas dependen mucho de la colaboración y la motivación de los equipos
Este tipo de contratos trata de reflejar principios del Manifiesto Agile, en el que se promueven iteraciones cortas que aporten valor y estén centradas en este y no en un alcance fij minimizando los riesgos de ambas partes. Es esencial que en las primeras fases empecemos con sprints de confianzas que generen esas sinergias entre clientes y proveedores
Historias de Usuario
Las historias de usuario son la unidad de trabajo más pequeña de un marco ágil. Es un método de toma de requisitos expresado desde la perspectiva del usuario del software.
Venimos de construir proyectos usando un documento de análisis funcional enorme complementado con unos prototipos. Pero este modelo siempre genera incertidumbres que resolver y expectativas difícil que cubrir, sin una estrecha colaboración y una acotación de los requisitos y la expectativa.
Este método archiconocido nos ayuda a establecer los alcances, junto a unos criterios de aceptación que acotan la funcionalidad. Nos apoyamos en ejemplos empleando “Specification by Example” para terminar de complementar esa Historia de Usuario.
Además esta unidad de medida, nos ayuda a construir User Story Mappings para plantear los roadmaps de los MVPs de nuestros clientes y priorizarlos con ellos para aportar el máximo valor.
Al final trabajar sobre este marco es un WIN WIN, ya que el cliente construye exactamente lo que necesita, y a nosotros nos ayuda a planificar nuestros sprint, analizar las desviaciones y dar estimaciones más realistas.
Equipos Multidisciplinares
Otro punto importante, es trabajar en equipos multidisciplinares. Se puede definir “equipo multidisciplinar” como un conjunto de personas, con diferentes formaciones académicas y experiencias profesionales, que operan en conjunto, durante un tiempo determinado para resolver un objetivo común.
Es evidente que la diversidad de perfiles enriquece y genera distintas perspectivas y soluciones generando compromiso y trabajo en equipo. En la construcción de los productos nos ayuda a entender de manera transversal los requisitos, mejorando la comunicación entre los distintos equipos de UX, UI, Desarrollo, QA o SEO.

Un concepto interesante es el de mesas calientes que pueden ir rotando a lo largo del tiempo. Se trata de sentarse juntos un equipo formado por perfiles distintos trabajando en el mismo proyecto. Es importante evitar totalmente silos, todas las áreas deben trabajar en conjunto en este mismo proyecto, evitando burocracias de departamentos que ralentizan el proceso.
Atomic Web Design
Otro aspecto importante es el uso de Atomic Web Design. Esta estrategia orientada a UI nos ayuda a construir el diseño de una interfaz web descomponiendo en unidades más pequeñas, denominados átomos, moléculas, organismos y plantillas, reutilizando estos componentes a través de la composición para generar elementos más grandes y potentes que compongan todo el diseño.
Aunque parezca ligado solo a diseño es importante tomar esta práctica de forma transversal uniendo disciplinas. En nuestros desarrollos usamos frameworks javascript orientados a componentes como ReactJS o Vue. Es importante que haya una trazabilidad entre lo diseñado y lo construido, permitiendo implementar de manera más eficiente los cambios sobre los componentes y poder realizar prototipos y pruebas de conceptos con estas piezas
Performance Review
En los últimos meses estamos comenzando a realizar Performance Reviews. Se tratan de revisiones del desempeño de una persona y de su contribución a la organización comparándolo con la última revisión. Creo imprescindible mantener al equipo motivado, con objetivos claros y con una progresión clara para entender sus necesidades y ayudarles en su crecimiento personal.
Es importante que estos objetivos sean alcanzables en tiempos cortos, no ser muy ambicioso y que la comunicación feedback fluya de forma constante y bidireccional apoyándonos en herramienta como el OneToOne.
Hace poco, debido al confinamiento, hemos puesto en práctica el uso de una herramienta de feedback que permite enviar aplausos para valorar el trabajo de los compañeros durante la semana. Este tipo de prácticas como pueden ser los Celebration Grid, los Kudos o los Exploration Days ayudan a sentirse realizado y dar lo mejor de uno mismo en los proyectos.
Testing / QA
Cultura del Testing
Desarrollar una cultura del testing dentro de la organización es esencial. El testing debe de verse como un aliado y no como lo primero que se descarta de un proyecto. El testing esta herramienta que nos asegura que nuestro proceso de CI/CD puede ejecutarse, poniendo cosas en producción asegurando y confiando la release que ponemos en producción
Nos podemos apoyar en herramientas como TDD, BDD o Gherkin, pero es esencial que el testing esté incluido en la propia tarea y que desarrollemos tests por cada bug que nos encontremos en producción
Teniendo esta base de testing en nuestras aplicaciones podemos realizar refactoring sin miedo al error, aumentando la productividad y resolviendo bugs de manera temprana. Para ello nos apoyaremos en la pirámide del testing, sin olvidarnos de tests de estrés y carga en aquellas aplicaciones que requieran un gran volumen de tráfico.
Equipo de QA
Además es esencial hoy en día contar con un equipo de QA, por que ya es una necesidad y no un lujo. Gracias a un equipo de QA y sus procesos aseguramos que el producto que entregamos cumple con los estándares de calidad adecuados.
Este proceso ayuda a detectar defectos antes que el producto esté en manos del cliente o de los propios usuarios, aumentando la satisfacción de estos.Es ideal que QA esté en todo el proceso, cercano desde la definición de requisitos y en todos los ámbitos asegurando la calidad de los entregables. Podéis descubrir más sobre equipos de QA a través del gran artículo de mi compañera Vicky Alonso
Continuous Integration
Y llegamos a la Integración Continua, donde vamos a ejecutar de manera nuestro software en cada cambio para detectar problemas de manera anticipada y asegurar que todo está en orden.
Pipeline as a code
Para ello diseñaremos nuestros workflows de CI usando una estrategia de Pipeline as a Code, escrita en un DSL específico, generalmente YAML, que estará versionado y disponible para todos los desarrolladores. Para ello existen multitud de herramientas SaaS que ayudan a definir estos workflows: CircleCI, Azure Devops, Github Actions, Travis CI, Bitbucket Pipelines.
Esto ayuda a dejar documentado de forma implícita como se construye el software, como se testea, que servicio se necesitan levantar, qué tipo de tareas hay que ejecutar y qué conjunto de datos necesita arrancar. Muy útil si trabajamos con software distribuido dentro de un monorepo y queremos probar la orquestación de cada pieza.

Automatizaciones
Además de todo eso, nos ayudará a mantener la consistencia en nuestro código, validando que cumplimos con las rules que haya establecido el equipo. Para ello nos podemos apoyar en herramientas como PHP-CS-Fixer, Husky o Prettier.
También podemos usar herramientas de análisis estática que nos analiza de una forma objetiva la estructura de nuestro código para identificar problemas y potenciales bugs e identifica código que no se alcanza, código duplicado, variables no inicializadas. Estas herramientas son muy útiles para obtener unas primeras sensaciones de manera objetiva de un proyecto legacy o externalizado. Además a los propios stakeholders (PO, PM) del proyecto les podemos ofrecer cierto KPIs durante el desarrollo para dar visibilidad y transparencia de estos.
Las posibilidades dentro del proceso de integración continua son infinitas, y además de los steps clásicos, podemos incluir más procesos que apoyen a cumplir con los objetivos y requisitos del proyecto. Algún ejemplo puede ser utilizar el CLI Lighthouse (https://github.com/GoogleChrome/lighthouse) para monitorizar nuestro performance, o Pa11y (https://github.com/pa11y/pa11y) para auditar si cumplimos con los standards de accesibilidad.
Continuous Deployment
Una vez que nos aseguramos que nuestro software está funcionando correctamente, tenemos que automatizar la puesta en producción de nuestro software utilizando la filosofía de la metodología DevOps, que se centra en la colaboración, la entrega y el despliegue continuo.
Es importante para cumplir con un corto Time to Market, que los ciclos de entrega sean cortos y la automatización, evitando la intervención humana nos va ayudar a reducir el riesgo.
Para no frenar los despliegues y facilitar el trabajo del equipo de QA podemos apoyarnos en “branches deploy” o “feature flags”, que nos ayudan a activar o desactivar funcionalidad en runtime.
No debemos de olvidarnos de prácticas como la administración de la configuración y secrets, la gestión de los secrets y la Infrastructure as a Code.
Serverless
En nuestro escenario nos apoyamos en la computación en la nube en el modelo Serverless. Serverless es un modelo de ejecución de software en la nube que se responsabiliza de ejecutar nuestro código en producción mediante una asignación generalmente abstracta y dinámica de los recursos. Esta aproximación nos permite centrarnos en el propio desarrollo y evolucionarlo, sin preocuparnos de mantenimientos y operaciones sobre máquinas virtuales.
En este escenario, es importante contar con los distintos servicios que nos ofrecen las nubes desde los modelos PaaS (Platform as a Service), pasando por FaaS (Function as a Service) hasta apoyándonos en funcionalidad de servicios SaaS.
Algunos ejemplos pueden ser:
- Si hablamos de PaaS, uno de los pioneros fueron Heroku, pero ya todos los proveedores Cloud cuentan con este tipo de servicios como Firebase, AWS ElasticBeanstalk o Azure AppService
- Si hablamos de FaaS, contamos con multitud de servicios que nos ayudan a desacoplar y apoyarnos en ellos para trabajar con arquitectura de microservicios, como pueden ser Firebase Functions, Azure Functions o AWS Lambda.
- Si lo que necesitamos es no reinventar la rueda, podemos apoyarnos en muchos servicios SaaS que nos ofrecen funcionalidad que solo tenemos que integrar en nuestros desarrollos. Por ejemplo, toda la parte de mail marketing y marketing automation podemos apoyarla en servicios como Sendgrid, Mailchimp o Sendinblue. Lo mismo con otros tipos de herramientas como Twilio, Stripe o Zapier.
La mayor ventaja de este modelo es que el coste no es fijo, en función de los recursos que necesite, el coste es por el uso que le des y al estar interactuando con otros servicios de la misma nube, tienen gran integración y monitorización para tener visibilidad sobre nuestra infraestructura.
Twelve Factors
Cuando construimos aplicaciones orientadas en la nube buscamos desarrollar aplicativos escalables, sin estado y fácilmente portables que cumplan los Twelve Factors (https://12factor.net/es/) Este dodecálogo una metodología para construir aplicaciones en la nube y algunos de esos factores interesantes a tener en cuenta son:
- Codebase: El código base de la aplicación es único, sin embargo, puede haber tantos despliegues de la aplicación como sean necesarios. Un despliegue es una instancia de la aplicación que está en ejecución. Si hay múltiples códigos base, no es una aplicación – es un sistema distribuido. Cada componente en un sistema distribuido es una aplicación, y cada uno, individualmente, puede cumplir los requisitos de una aplicación “Twelve-factor”.
- Backing Service: Un backing service es cualquier recurso que la aplicación puede consumir a través de la red como parte de su funcionamiento habitual. Entre otros ejemplos, podemos encontrar bases de datos (como MySQL o CouchDB), sistemas de mensajería y de colas (como RabbitMQ), los servicios SMTP de email o sistemas de cache.
El código de una aplicación “twelve-factor” no hace distinciones entre servicios locales y de terceros. Para la aplicación, ambos son recursos conectados, accedidos mediante una URL u otro localizador o credencial almacenado en la config. Un despliegue de una aplicación “twelve-factor” debería ser capaz de reemplazar una base de datos local MySQL por una gestionada por un tercero sin ningún cambio en el código de la aplicación. - Stateless: Las apps “twelve-factor” no tienen estado, cualquier información que necesite persistencia se debe almacenar en un ‘backing service’ con estado, habitualmente una base de datos. Algunos sistemas webs dependen de “sticky sessions”, esto quiere decir que cachean la información de la sesión de usuario en la memoria del proceso de la aplicación y esperan peticiones futuras del mismo visitante para redirigir al mismo proceso. Las “sticky sessions” son una violación de “twelve-factor” y no deberían usarse nunca ni depender de ellas. La información del estado de la sesión es un candidato perfecto para almacenes de información que ofrecen mecanismos de tiempo de expiración, como Memcached o Redis.
- Gestión de la configuración: Las aplicaciones “twelve-factor” almacenan la configuración en variables de entorno. Las variables de entorno se modifican fácilmente entre despliegues sin realizar cambios en el código; a diferencia de los ficheros de configuración, en los que existe una pequeña posibilidad de que se guarden en el repositorio de código accidentalmente. Las envvars son un estándar independiente del lenguaje y del sistema operativo.
Conclusión: El final del camino hacia CI/CD
Tras este camino hemos llegado a nuestro destino en el que se prometió llegar hasta CI/CD. Tras hacer un recorrido por las distintas prácticas que creo hoy en día indispensables llegando a una conclusión: Personas e interacciones, sobre procesos y tecnología y siempre buenas prácticas.



